Abstract
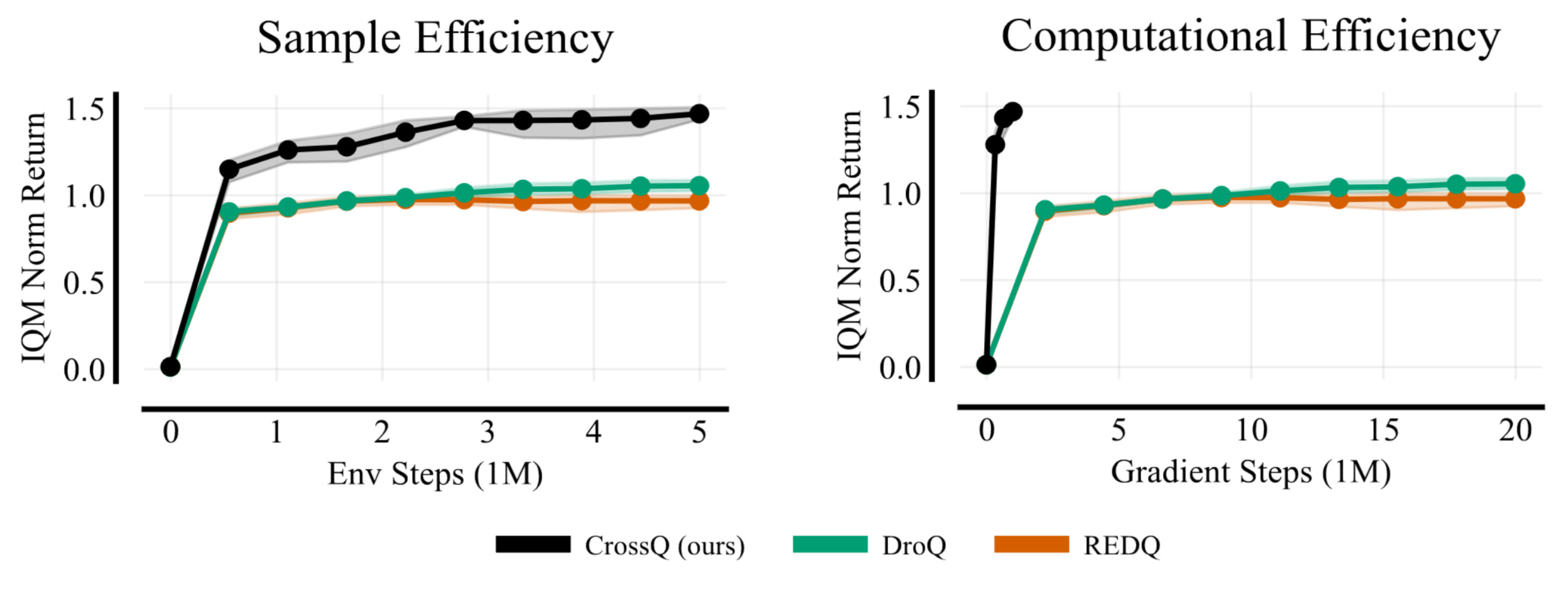
Sample efficiency is a crucial problem in deep reinforcement learning. Recent algorithms, such as REDQ and DroQ, found a way to improve the sample efficiency by increasing the update-to-data (UTD) ratio to 20 gradient update steps on the critic per environment sample. However, this comes at the expense of a greatly increased computational cost.
To reduce this computational burden, we introduce
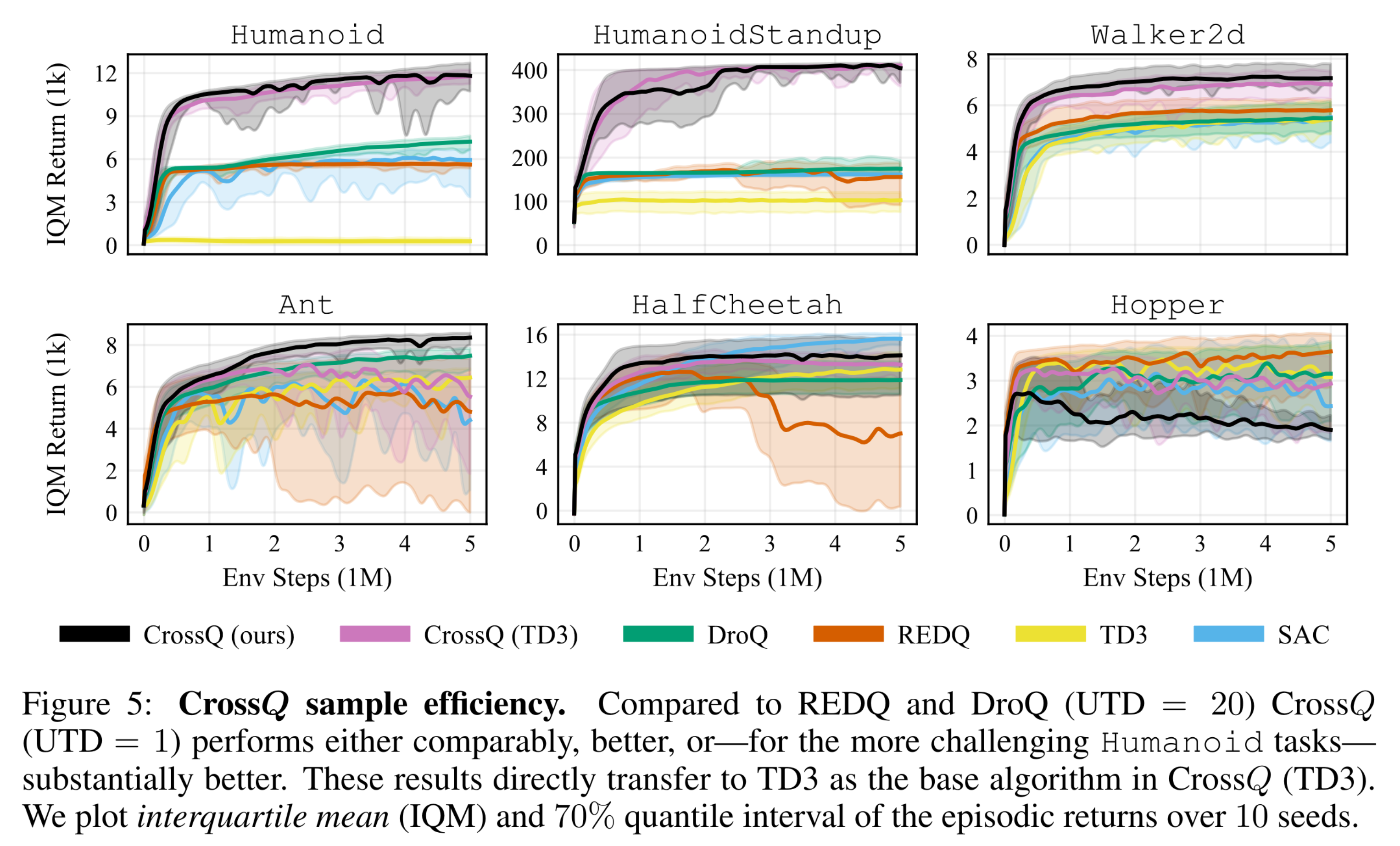
- it matches or surpasses current state-of-the-art methods in terms of sample efficiency,
- it substantially reduces the computational cost compared to REDQ and DroQ,
- it is easy to implement, requiring just a few lines of code on top of SAC.
TL;DR
Problem
We want fast + simple + sample-efficient off-policy Deep RL.- UTD=1 methods — like SAC and TD3 — are fast, but not sample-efficient enough
- UTD=20 methods — like REDQ and DroQ — are sample-efficient, but not fast enough
- High-UTD training requires Q-function bias reduction, making algorithms more complex
Insight
BatchNorm greatly accelerates convergence in Supervised Learning. Can it similarly accelerate RL?We show that naively using BatchNorm with Q networks is harmful:
- TD learning relates Q predictions from the forward passes of two batches — (S, A) and (S', A')
- Both batches in TD have different statistics: A comes from the replay, A' comes from the policy
- BatchNorm's mismatched running statistics degrade Q predictions and harm training
Solution
- Delete the target network
- Concatenate the batches (S, A) and (S', A') into one, and do a single forward pass
BatchNorm now uses normalization moments from the union of both batches. These moments are not mismatched, as all inputs now belong to the same mixture distribution.

CrossQ
To turn SAC into - Delete target nets, simplifying the algorithm
- Use batch normalization, boosting sample-efficiency by an order of magnitude
- Widen the critic, further improving performance
These changes take only a few lines of code.
Try

Read









Cite
@inproceedings{
bhatt2024crossq,
title={CrossQ: Batch Normalization in Deep Reinforcement Learning for Greater Sample Efficiency and Simplicity},
author={Aditya Bhatt and Daniel Palenicek and Boris Belousov and Max Argus and Artemij Amiranashvili and Thomas Brox and Jan Peters},
booktitle={International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=PczQtTsTIX}
}