Open-Loop Dexterous Manipulation with a Robot Hand
During RSS 2021, my colleagues and I published a surprising new finding. It turns out, the softness of hands lets us manipulate some objects completely blind: without any visual/tactile/force feedback. We studied the nature of these open-loop skills, and identified three key design principles for robust in-hand manipulation. Watch the video below.
This video shows a soft robotic hand
- No cameras
- No motion capture
- No proprioception
- No kinematic models
The pneumatic
So why the heck does this work? It's been known for a while that compliant, underactuated grippers greatly simplify object grasping: when an object is near enough, just close all the fingers — without looking — and they wrap around the it, conforming to its shape
In wrapping around the object, soft hardware "reacts" to the shape of the object in a very useful way, essentially freeing you from having to do that in code (or training a neural network to do that). Of course, this doesn't work in all cases, and sometimes you really do have to carefully plan grasps. . Now this effect would be difficult to get with a rigid, fully-actuated hand. We've shown here that this effect helps not only with power grasps, but also with fine manipulation. In fact, it is central to in-hand manipulation!
These open-loop skills are also resilient to a fair amount of variability in object placement. See below: a manipulation episode can start out with somewhat different initial conditions every time, and the skills work just fine with a wide range of those. Note that we do not sense or track the object to adjust the actuation.
These skills seem quite robust, and because they return the object to roughly the same spot where it started out, we can loop their execution to see just how robust they are. While manually editing these inflation sequences, we treated the number of successful loops — an empirical quantification of robustness — as an objective to maximize. Below, you can see that we were able to loop the complex Twist + Pivot + Finger-Gait + Shift combination 54 times, and the simpler Spin + Shift sequence a whopping 140 times before the cube dropped out.
Mind you: all of this is executed completely blind, with no sensory feedback to correct mistakes. So how, exactly, did we design these skills?

The RBO Hand 3 has 16 actuators. We control it by commanding air-mass "goals" in milligrams for each actuator. So any one vector of 16 numbers prescribes one hand posture.
We commanded these actuation signals using a large mixing-board (typically used by DJs for mixing music).

We first observed ourselves manipulating cubes in our own hands. We then tried to copy some moves onto the robot. To do so, we placed a wooden cube on the robot hand, and moved the sliders back and forth to get the cube to turn 90 degrees. Once we perfected the manipulation strategy, we saved intermediate snapshots of these inflation levels as keyframes

Let's stop and think about what's happening here: in-hand manipulation is a hard problem that involves considerations of object geometry, planning contact points, balancing interaction forces, etc. All of these things matter. But we just showed here that you can bypass the explicit handling of those things, well enough that a fixed open-loop policy is able to generalize in order to manipulate different objects with different initial conditions.
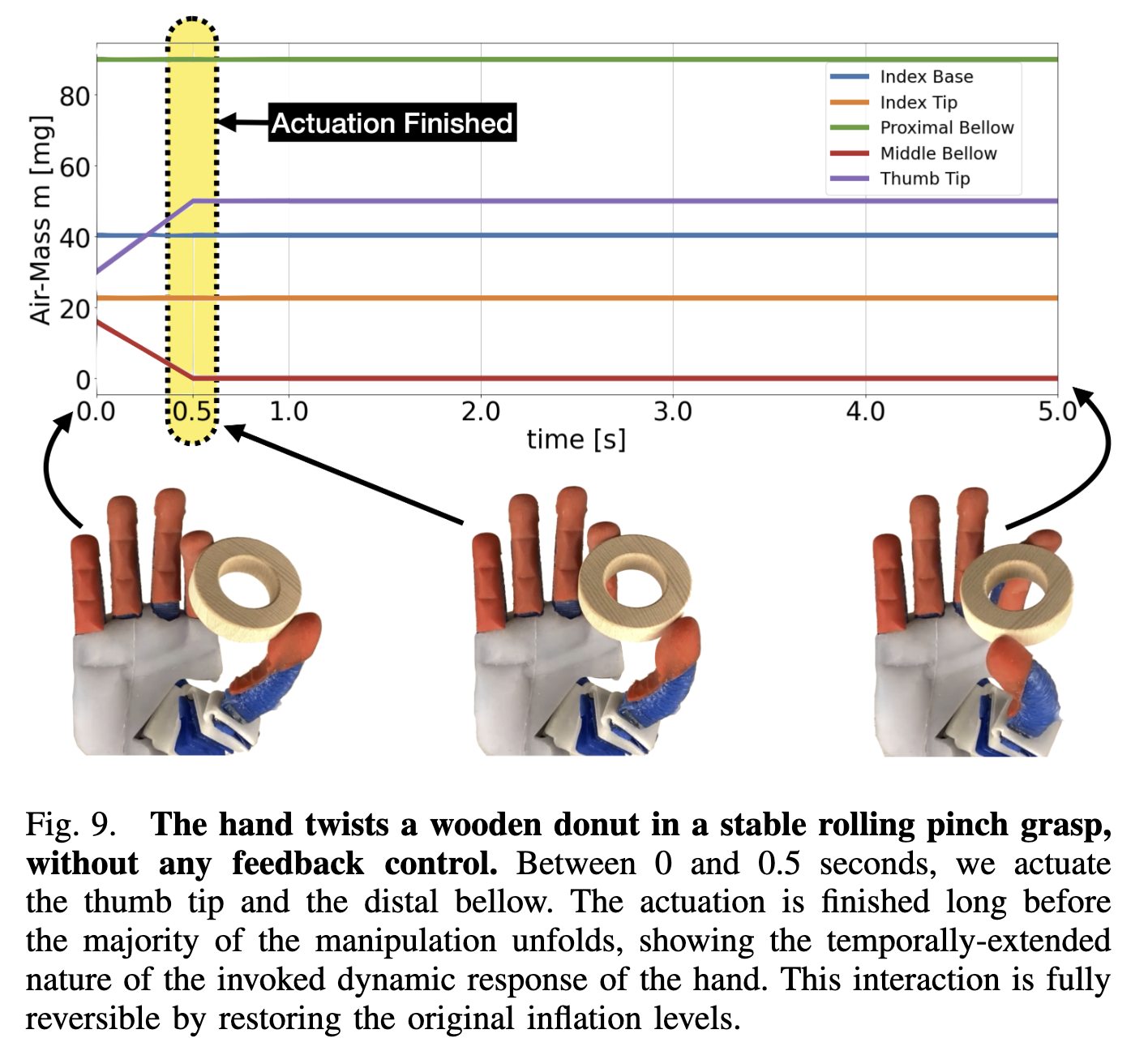
In the video below, we explain this idea by getting the hand to twirl a wooden donut, using an absurdly simple control signal.
Let's step back and take a moment to absorb this. This donut-twirling skill would be super hard to design with a fully-actuated rigid robot hand. You'd probably need force sensors, maybe a geometric model of the donut, inverse kinematics for the fingertips, and a whole lot of math to tie it all together. That problem would involve maintaining adequate contact forces, planning a trajectory, and maybe tracking the object and finger positions along the way.
A different paradigm: Hardware-Accelerated Robotics
The springy hardware, when placed in certain situations, exhibits behaviors that I like to call Funky Dynamics
Much like we offload expensive matrix multiplications, convolutions, and graphics routines to GPUs, we can offload control primitives to capable hardware. This leaves us with a much simpler control problem: that of pulling a few strings to puppeteer the physics. This hardware acceleration gives us — as a foundation — things we like in a control policy:
- Robustness
- Simplicity
- Generalization
Let's talk about generalization for a bit. Imagine a control policy function looks like a neural network. There's no reason it should be one, but it helps me (an RL guy) as a thought scaffold, and perhaps it will help you.
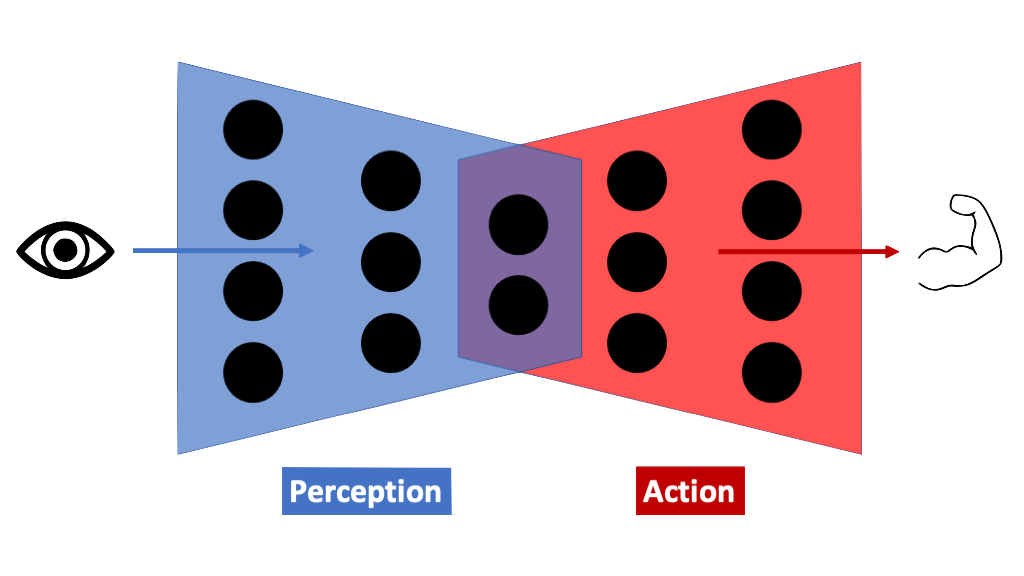
A control policy function has two ends: an input (the perception side), and an output (the action side). Generalization is often discussed in the context of perception: e.g. ConvNets train and generalize better than simple fully-connected MLPs because convolution presupposes some degree of translation invariance, among other priors. Fewer works talk about generalization in the case of action. Much like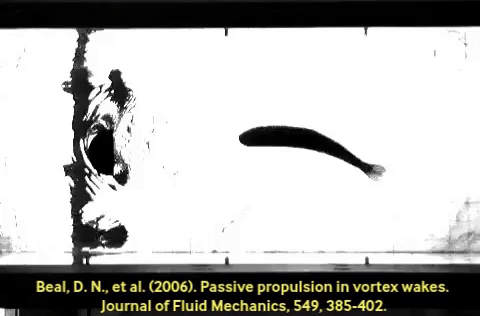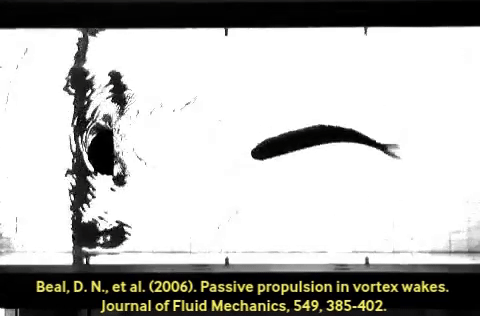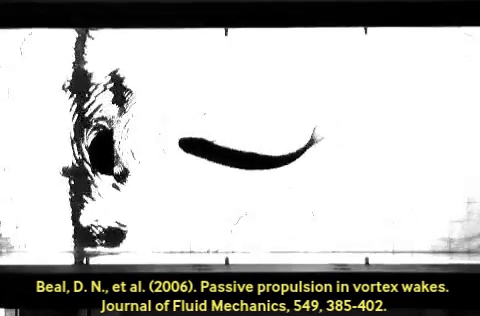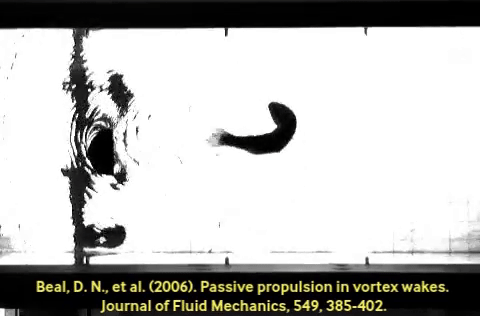 A neat and famous example is the dead fish swimming upstream. This fish body was optimized through evolution to subsume a large part of the swimming policy; imagine the last layer of the policy network above, implemented in body shape and meat. Co-design of policy and morphology is an active area of research. Convolution on the perception side, compliant hardware can alias similar-but-different situations in a useful way.
A neat and famous example is the dead fish swimming upstream. This fish body was optimized through evolution to subsume a large part of the swimming policy; imagine the last layer of the policy network above, implemented in body shape and meat. Co-design of policy and morphology is an active area of research. Convolution on the perception side, compliant hardware can alias similar-but-different situations in a useful way.
Case in point: below, the exact same actuation signal twirls not only that donut, but also cubes, wedges, pyramids, and cylinders (we did not tweak the actuation to make this work; it generalized on the first try).
Constraining the Dynamics to be Funnel-Shaped
Behaviors like the twirl here are primitives. To build more interesting skills, we must sequence these primitives into chains. That means the result of one primitive movement must be an acceptable precondition of the next. Thanks to the nice qualities of generalization and robustness, the precondition sets of these primitives are rather "tolerant". That said, we must still do the hard work of making sure these primitives align together.
But instead of explicitly controlling things, we're just surfing the physics, so we can't really ask the hand to achieve exact desired object positions. What we can do instead, is to tame the funky dynamics of these primitives by tweaking them — with actuation — to be highly predictable in whatever they do. That means, we leverage the physics as the main "driver" of the movement, and robustify it using carefully crafted physical constraints.

This is called constraint exploitation: we reduce the position uncertainty not through sensing and tracking, but instead through actions that, by construction, will narrowly restrict some system feature to a small known range of values (in the doodle above, that feature is the planar rotation angle, but it could be anything). Skills — or primitives — that do such things robustly are called Funnels
Sequence your Funnels to build Robust Skills
Funnel-like policies are cool thanks to their potential for compositionality. If you've got two funnels, and one funnel's exit resides in the other funnel's entrance, you can blindly execute them in a sequence, and know the eventual outcome before you even begin. What's more, each funnel sequence is also a funnel in its own right. This lets us compose long, dexterous manipulation skills.
Funnels don't need to be open-loop! But we already had a bunch of nontrivial open-loop skills, and wanted to see how far we could take this. We robustified our skills with carefully chosen actions, and after lots of careful fine-tuning, were able to build giant skill sequences like this demo below. None of the movements here are specific to any of the cubes' shapes.
We think these design principles could be very powerful inductive biases for robotic reinforcement learning approaches. I hope to explore these ideas in my future research.
Paper: http://www.roboticsproceedings.org/rss17/p089.pdf
RSS 2021 Spotlight Talk