Deep Reinforcement Learning without Target Networks

Some of the most data-efficient Reinforcement Learning algorithms are off-policy methods: they learn from stored fragments of past experiences, piecing together long-term predictions using Temporal Difference (TD) learning. Unfortunately, off-policy Deep RL training is numerically unstable and runs the risk of divergence. Methods published after 2015 mitigate this problem by doing something different from the textbook definition of TD learning: they compute the TD regression target using the output from a target network: a slow-moving copy of the trained Q network. Unfortunately, this stability comes at the cost of slower learning, because it uses stale Q estimates as the regression targets.
I was intrigued by the possible existence of an alternative way to stabilize off-policy Deep RL. In my Masters thesis project, I discovered a workaround to target networks: a surprisingly simple tweak to Batch Normalization mitigates turns neural off-policy TD stable!
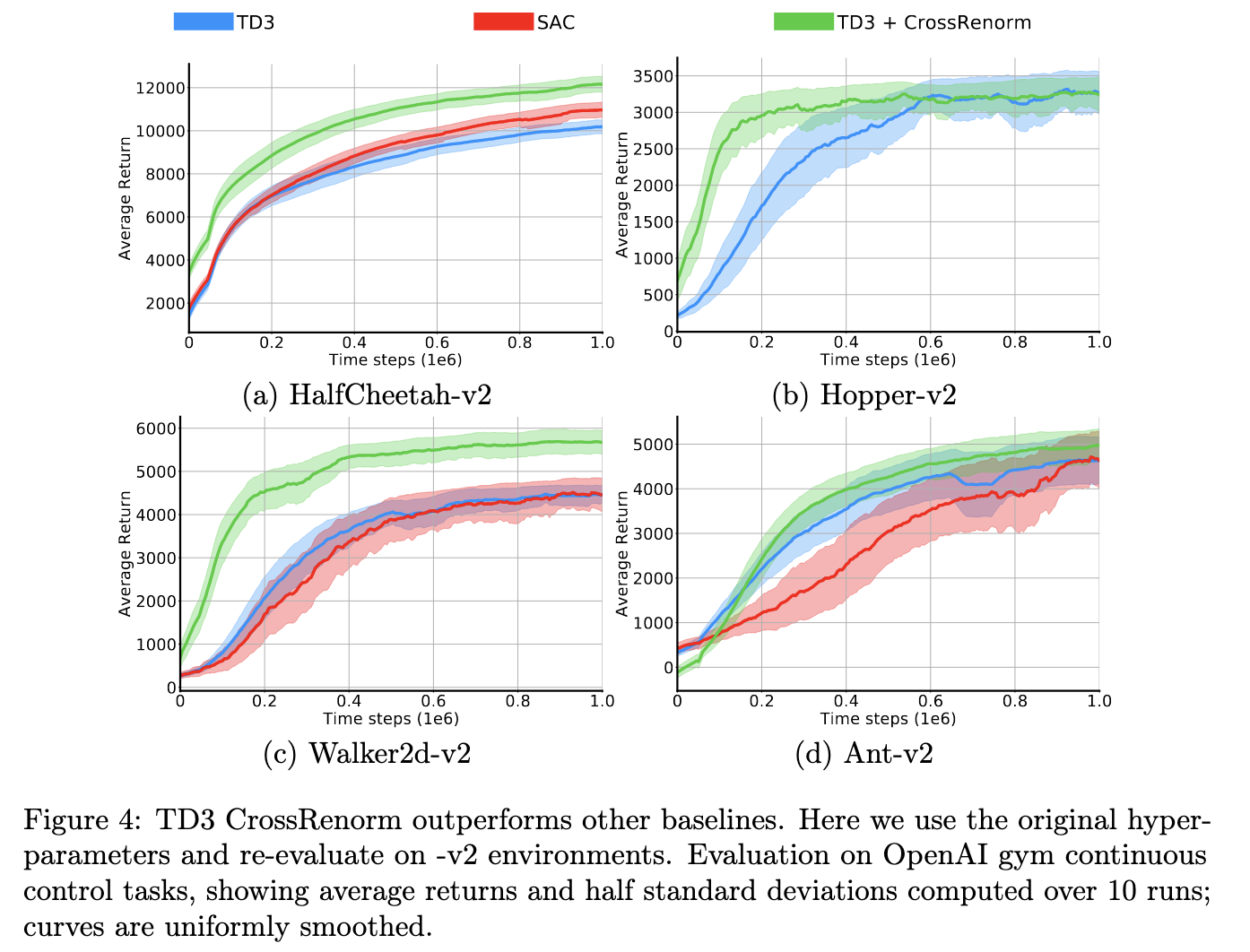
This trick, which we called CrossNorm, removes the need for target networks — letting you use the textbook TD loss — and simultaneously improves the network's numerical conditioning, greatly speeding up agent training. Along with my thesis mentors Max and Artemij, we tried to probe the theoretical underpinnings of this stabilizing effect, and also ran experiments to quantify its improvements upon state-of-the-art baselines like TD3 and SAC.
Paper: CrossNorm: Normalization for Off-Policy TD Reinforcement Learning
Thesis: Masters Thesis